Data management is quintessential, which is why Wilfried Lemahieu, Seppe vanden Broucke and Bart Baesens wrote the book ‘Principles of Database Management’, as a practical guide to storing, managing and analyzing big and small data. We asked them a couple of questions about data management.
Why did you decide to write your book Principles of Database Management?
This book is the result of having taught an undergraduate database management class and a postgraduate advanced database management class for more than ten years at KU Leuven (Belgium). Throughout these years, we have found no good textbook which covers the material in a comprehensive way without getting flooded by theoretical detail and losing focus. Hence, after having teamed up together, we decided to start writing a book ourselves. This work aims to offer a complete and practical guide covering all the governing principles of database management, including:
- End-to-end coverage starting with legacy technologies to emerging trends such as Big Data, NoSQL databases, Analytics, data governance, etc.
- A unique perspective on how lessons learnt from past data management could be relevant in today’s technology setting (e.g., navigational access and its perils in Codasyl and XML/OO databases)
- A critical reflection and accompanying risk management considerations when implementing the technologies considered, based on our own experiences from participating in data and analytics related projects with industry partners in a variety of sectors, from banking to retail and from government to the cultural sector
- Offering a solid balance between theory and practice, including various exercises, industry examples and case studies originating from a diversified and complimentary business practice, scientific research and academic teaching experience
We hear a lot of companies complaining about bad data quality these days. How can database management contribute to this?
First of all, data quality (DQ) is often defined as ‘fitness for use,’ which implies the relative nature of the concept. Data of acceptable quality in one decision context may be perceived to be of poor quality in another decision context, even by the same business user. For instance, the extent to which data is required to be complete for accounting tasks may not be required for analytical sales prediction tasks. Database management can contribute in various ways to improving data quality.
A good conceptual data model capturing the business requirements as accurately as possible is the start of everything. As discussed in the book, both EER and UML can be used for this purpose. It is important to also list the semantic shortcomings of the conceptual models developed such that they can be followed up during application development.
A next important activity concerns metadata management. Just as raw data, also metadata is data that needs to be properly modeled, stored and managed. Hence, the concepts of data modeling should also be applied to metadata in a transparent way. In a DBMS approach, metadata is stored in a catalog, sometimes also called data dictionary or data repository, which constitutes the heart of the database system.
Finally, to manage and safeguard data quality, a data governance culture should be put in place assigning clear roles and responsibilities. The ultimate aim of data governance is to set up a company-wide controlled and supported approach towards data quality, accompanied by data quality management processes. The core idea is to manage data as an asset rather than a liability, and adopt a proactive attitude towards data quality problems. To succeed, it should be a key element of a company’s corporate governance and supported by senior management.
Many companies are investing in data lakes these days. What is the difference with a data warehouse?
Much more recent than data warehouses, the data lake concept became known as part of the big data and analytics trend. Although both data warehouses and data lakes are essentially data repositories, there are some clear differences as listed in the table below.
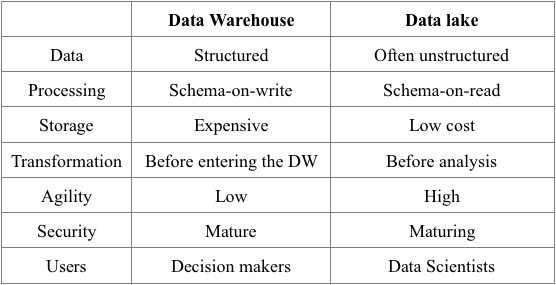
A key distinguishing property of a data lake is that it stores raw data in its native format, which could be structured, unstructured or semi-structured. This makes data lakes fit for more exotic and ‘bulk’ data types that we generally do not find in data warehouses, such as social media feeds, clickstreams, server logs, sensor data, etc. A data lake collects data emanating from operational sources ‘as is’, often without knowing upfront which analyses will be performed on it, or even whether the data will ever be involved in analysis at all. For this reason, either no or only very limited transformations (formatting, cleansing, …) are performed on the data before it enters the data lake. Consequently, when the data is tapped from the data lake to be analyzed, quite a bit of processing will typically be required before it is fit for analysis. The data schema definitions are only determined when the data is read (schema-on-read) instead of when the data is loaded (schema-on-write) as is the case for a data warehouse. Storage costs for data lakes are also relatively low because most of the implementations are open-source solutions that can be easily installed on low-cost commodity hardware. Since a data warehouse assumes a predefined structure, it is less agile compared to a data lake which has no structure. Also, data warehouses have been around for quite some time already, which automatically implies that their security facilities are more mature. Finally, in terms of users, a data warehouse is targeted towards decision makers at middle and top management level, whereas a data lake requires a data scientist, which is a more specialized profile in terms of data handling and analysis.
Is there any additional material provided (e.g., for instructors or students)?
Yes, the book comes with the following additional material:
- A website with additional information: www.pdbmbook.com
- Free YouTube lectures for each of the 20 chapters
- PowerPoint slides for each of the 20 chapters, see http://www.pdbmbook.com/lecturers
- A solutions manual with the solutions to all multiple choice and open questions.
- An online playground with diverse environments, including MySQL for querying; MongoDB; Neo4j Cypher; and a tree structure visualization environment
- Full-color illustrations throughout the text
- Extensive coverage of important trending topics, including data warehousing, business intelligence, data integration, data quality, data governance, Big Data, and analytics
- Hundreds of examples to illustrate and clarify the concepts discussed that can be reproduced on the book’s companion online playground
- Case studies, review questions, problems, and exercises in every chapter