The Eurovision Song Contest is an annual song competition held, primarily, among the member countries of the European Broadcasting Union since 1956. Each member country submits a song to be performed on live television and radio and then casts votes for the other countries' songs to determine the most popular song in the competition. If you don’t know the most famous historical winners ABBA, Céline Dion and Julio Iglesias, you must have been living on a deserted island for some years.
For fans of facts & figures like myself, Eurovision is a dream theme to dig into, as many statistics and analytics about this phenomenon have been published on the world wide web. Besides all possible charts you can imagine (average points per country, best presenters, countries with null points, …), the yearly odds calculations (apparently a woman who sings in English and who performs last has much higher odds than a man who sings in Rumanian and who performs second or seventh), voting patterns between different countries have been thoroughly investigated.
As Eurovision is officially still a song contest (I agree we might forget this from time to time) I believed analyzing the text in the lyrics could show some interesting information and connections. I’m considered to be a real lyrics machine by my friends (some even call me ‘the jukebox’, meaning that I can usually sing along whatever song pops up) so it was a nice trip down memory lane for me to look up all the lyrics of the winning songs since 2000. All songs were in English except for Serbia’s winning song “Molitva” in 2007 of which I used the English translation.
Once I’d collected all the lyrics and put them together in a dataset, I was ready to start text mining with SAS Text Miner.
How does text mining work?
First thing that needs to happen in a text mining flow is the so called ‘text parsing’, using the Natural Language Processing capabilities of the software. Text parsing associates terms with parts of speech (verb, noun, adjective, …) and performs stemming to equate terms that are different verb tenses of the same verb, or to equate terms that are either singular or plural versions of the same noun. Another ability of the text parsing procedure is to handle a stop list: a dictionary of terms to be ignored in the analysis (specified by the user).
Once the text parsing is completed and all terms in the document collection have been identified, the text filter node needs to be run. This process calculates the weight of every single term in the document collection, based on the total frequency and the number of documents in which the term appears. There’s a ‘check spelling’ property included which uses a spelling dictionary and word-similarity algorithms to find and correct misspellings.
The output of the text filter process can be visualized in a word cloud.
What is the most frequent word in the winning songs?
In this word cloud we see the 30 most appearing terms in the song lyrics of the past 15 winners of the Eurovision Song Festival.
The size of the term indicates the number of songs in which it appears
The color represents the total frequency of the term
The + sign means that the term has been stemmed and several forms of this word are considered here.
It probably doesn’t come as a surprise that the term ‘love’ is the absolute winner: it appears in 8 out of the 15 song lyrics and it can be observed 67 times in total. Of course some terms were present in more songs, like ‘to be’ but I included this in the stop list because it’s not a very significant word.
Which groups of songs can we identify?
Finding out about the terms is interesting, but it’s even more exciting to discover different groups into the different songs. If we want to perform statistical document clustering, we need algorithms to process the terms matrix into numerical representations. This is exactly what the Singular Value Decomposition (SVD) algorithm does: it reduces the dimensions of the term-document frequency matrix by transforming the matrix into a lower dimensional, more compact, and informative form.
As a last step in this text mining exercise, I used the Text Cluster node to cluster the lyrics into disjoint sets of songs. SAS Text Miner is suggesting three different clusters:
The first cluster consists of six songs that could be labeled ‘Power songs’. They are about believing in yourself, taking opportunities, never giving up … Most of these songs were performed by male artists from Northern and Eastern Europe. Except for one song, they date from rather recent editions of the Eurovision Song Festival.
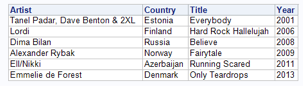
The next cluster is somewhat the counterpart of the previous. It contains five songs by female artists, mainly from Southern Europe. The most recent song in this cluster dates from five years ago already. The lyrics are somewhat bittersweet and talk essentially about the importance of a significant other, the pain of being apart, the sacrifices they are willing to do for their other half…
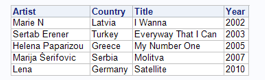
In the third and last cluster we can find four optimistic songs about positivism, love and happiness. From a geographical point of view we recognize the same pattern as in the first cluster. The chronological construction of this cluster is rather remarkable as there is a gap of eight years between the second and the third song.
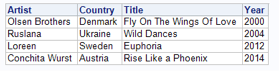
Based on this analysis, I would put my money on a power song, from a Northern or Eastern European country by a male artist. Will the analytics prove to be right?
Image credit: ©Andres Putting, Elena Volotova (EBU)